
Macのローカル環境でAUTOMATIC1111版Stable Diffusion Web UIを使うための手順を説明します。
環境情報
PC:Mac Mini 2020
プロセッサ:Apple silicon (M1)
OS:macOS Ventura
メモリ:8GB
この記事の内容はM1 Macでの実証結果になりますが、M2など他のAppleプロセッサでも大きく変わらないと思われます。
Homebrewをインストール
動作に必要ないくつかのパッケージをインストールするため、Homebrew(Macのパッケージマネージャー)をインストールします。

ターミナルに公式サイトに記載されているコマンドをターミナルで実行すれば完了です。途中パスワード入力を求められ得るので、入力しEnterで継続してください。
Homebrewで必要なツールをインストール
ターミナルから以下のコマンドで必要なツールをインストールします。しばらく時間がかかります。
brew install cmake protobuf rust python@3.10 git wget以下のパッケージがインストールされます
cmake: プロジェクトのビルドプロセスを管理するためのクロスプラットフォームなビルドツールです。protobuf: Protocol Buffersとしても知られるGoogleのデータ交換形式のサポートパッケージです。rust: Mozillaによって開発されたシステムプログラミング言語Rustのコンパイラと関連ツールチェーンです。python@3.10: Pythonプログラミング言語の最新のメジャーバージョン(3.10)です。git: 分散バージョン管理システムであるGitのインストールパッケージです。wget: ネットワーク経由でファイルをダウンロードするためのコマンドラインツールです。
Stable Diffusionをダウンロード
Stable Diffusionをインストールしたいフォルダに移動します。
cd ~/"任意のフォルダパスを指定" #Home配下の移動したいフォルダその場所に Github のリポジトリトリをクローンします。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui移動したフォルダに stable-diffusion-webui フォルダが作成されます。
補足:Stable Diffusion Web UIのアップデート
時が経ち、AUTOMATIC1111 版 Stable Diffusion Web UI のアップデートが必要となった場合は、プログラムが起動してない状態で、stable-diffusion-webui フォルダのある場所へ移動し以下のコマンドを実行します。
cd ~/"stable-diffusion-webuiがあるフォルダパス"
git pull学習モデルをダウンロード
学習モデルをダウンロードします。ベーシックなサンプル学習モデルを記載しておきます。
stable-diffusion-v-1-4
stable-diffusion-v1-5
.ckpt ファイル、又は、 .safetensors ファイルを1つまたは複数ダウンロードして stable-diffusion-webui/models/Stable-diffusion フォルダに移動します。
以下のサイトから様々な学習モデルがダウンロードできるので、自分の好みに合った学習モデルを探してみてください。
モデルによっては商用利用が制限されている物があるため、商用利用する場合にはしっかり商用利用可能なモデルを利用しましょう。
Stable Diffusion Web UIを実行
stable-diffusion-webui フォルダに移動します。
cd ~/stable-diffusion-webuiバッチを実行しStable Diffusion Web UIを起動します。
※初回のみインストールも実行されるため時間がかかります。
./webui.shここでつまずく。。。
M1Macの場合(私の場合)は実行でエラーが出てしまい、うまく起動することや、起動できても画像生成することができませんでした。
/Users/karsten/miniconda3/envs/web-ui/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown warnings.warn('resource_tracker: There appear to be %d 'いろいろググって調べた結果、実行時に以下のパラメータも渡す事で解消されました。
./webui.sh --share --skip-torch-cuda-test --no-halfStable Diffusion Web UIを使う
実行コマンドを入力後、出力が止まり 「http://127.0.0.1:7860/」 が表示される。

ブラウザのアドレス欄に 「http://127.0.0.1:7860/」 と入力し、以下のような画面が出たら、起動成功です。
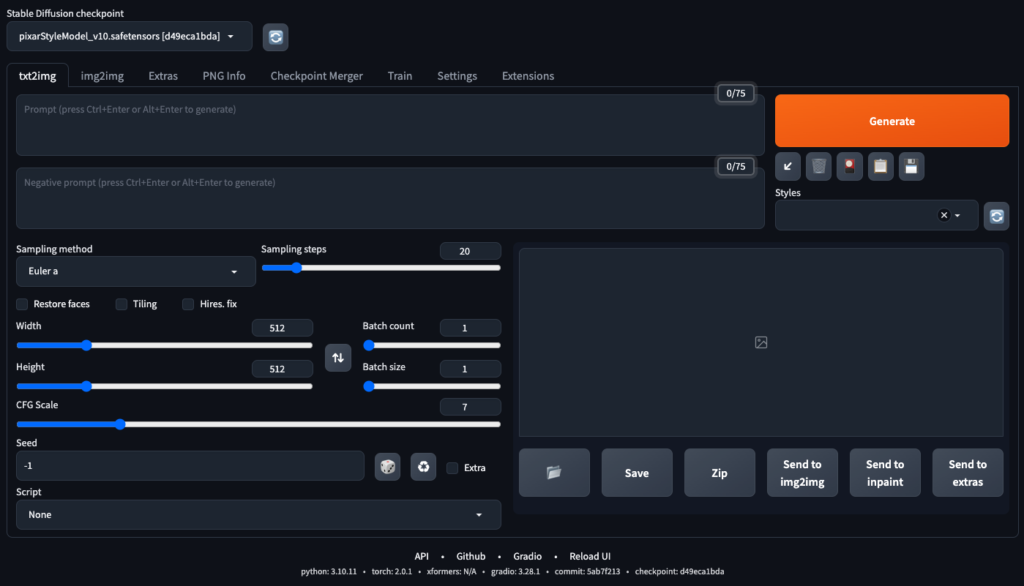
学習モデルの選択
ダウンロードして格納したモデルは左上の「Stable Diffusion checkpoint」にプルダウンで表示されます。使いたいモデルを選択して読み込みが終われば画像生成を始めることができます。
Stable Diffusion Web UIの各種パラメータ
| 1 | Sampling method | サンプリング方法 |
| 2 | Sampling steps | ノイズからイラストに変えていくための回数 |
| 3 | Restore faces | 顔を綺麗にできる(美人になるとは限らない) |
| 4 | Tiling | タイル状に並べる |
| 5 | Hires. fix | 解像度を上げることができる |
| 6 | Width, Height | 画像の横幅、高さ |
| 7 | Batch count | 画像の枚数(何回バッチを行うか) |
| 8 | Batch size | 画像の枚数(1回のバッチで何枚の画像を生成するか) |
| 9 | CFG Scale | どれだけプロンプトに近いイラストを生成するか |
| 10 | Seed | Seedの数値と他の設定によって絵が決まる。-1にするとランダム |
1.Sampling method
Sampling methodはサンプラーと言われる物で、ノイズを除去(サンプリング)する方法を選択できます。
基本的には利用する学習モデルが推奨するサンプラーを選択すると良いでしょう。
Sampling methodの中には「Ancestral samplers」と呼ばれるものがあり、これを使用するとSampling stepごとにイラストの形が変わります。
Ancestral samplersは名前に「a」がついています。
- Euler a
- DPM2 a
- DPM++ 2S a
- DPM++ 2S a Karras
- DDIM
- PLMS
イラストの再現性が必要ならEulerやDPM++ 2M Karrasなどの方がおすすめです。
2.Sampling steps
Sampling stepsはノイズを除去する回数です。
Sampling stepsの数が多いほど、1回で生成する画像のノイズ除去量は少なくて済むため、より丁寧にノイズが除去できるイメージになります。
Sampling stepsは数が多いほど質の高いイラストを生成することができますが、その代わり生成時間がかかるため、品質と時間のどちらを優先するかでstep数を決める必要があります。
デフォルトでは20になっていますが、30以上あれば十分綺麗な画像が生成できるイメージです。
また多すぎても精度は頭打ちとなります。
3.Restore faces
Restore facesにチェックを入れると、Generative Facial Prior GAN(GFPGAN)を用いて、そのままだと崩れがちな顔の補正を強力に行い、できるだけ左右対称を維持してくれます。
※全身像のような引きの絵で顔が小さめの場合は補正が効きません。
特に実写向きの機能で、二次元系のイラストではOFFが推奨されます。
4.Tiling
Tilingにチェックを入れると、画像をタイリングできます。つまり上下左右に繋ぎ目無く、綺麗に繋げられる画像を出力することができます。テクスチャや模様を生成したい場合にのみ利用sるため、人物などの生成ではOFFが推奨されます。
5.Hires. fix
Hires. fixにチェックを入れると以下の順に高解像度な画像が生成されます。
- 低解像度で画像を生成
- 1の画像をアップスケーラーというアルゴリズムで拡大
- 2の画像をimg2imgというモデルで詳細追加
このように生成ステップを分けることで、構図の破綻や画質の劣化を抑えつつ、高解像度な画像を生成することができます。
Hires. fixにチェックを入れると、以下の設定項目が出現します。
- Upscaler (アップスケーラー): 低解像度の元画像を拡大する際に用いるアルゴリズムの種類を指定します。10種類以上ありますが、それぞれ特徴や出力結果が異なるので個人で好みを探してみるのがいいでしょう。(SwinlR4×)
- Hires steps :高解像度化する際のステップ数。ステップ数が多いほど緻密になりますが、時間もかかります。0にするとサンプリングステップ数と同じ値が適用されます。通常は「0」のままか、サンプリングステップ数よりも小さい値で大丈夫です。
- Denoising strength (ノイズ除去度):アップスケーリングの元となる画像からどの程度ノイズ除去するか。この値を小さくするとアップスケール後に元画像とかけ離れた画像になりやすいです。逆に大きくすると元画像に忠実になりますが、滑らかすぎる場合もあります。0.6~0.7くらいがバランスが良くおすすめです。
- Upscale by (アップスケール倍率):何倍に拡大するか。1.5~1.6倍くらいが無難です。あまりに大きすぎるとGPUのメモリ不足でエラーが出る場合があります。
6.Width, Height
生成する画像の横幅と高さです。
値を大きくすると、より多くのVRAMが必要になります。あまり大きな値にすると、人数が勝手に増えたり、人体が崩れがちになります。
7.Batch count
画像生成を繰り返す回数で、VRAM使用量には影響しません。
Batch countが1なら1枚のイラストを生成して終わり。2ならその処理を2回繰り返して2枚のイラストを生成します。
8.Batch size
同時に生成する画像の枚数で、VRAM使用量に影響します。
Batch sizeが2なら2枚のイラストを並行して生成します。
(例) Batch count=4、Batch size=3の場合、画像は12枚生成されます。(3枚同時生成 x 4回 = 12枚)
9.CFG Scale
入力したPromptにどのくらい従わせるかを示す数値です。数字が大きいほどPromptに順守させた画像生成を行います。
ただ、上げ過ぎると画像が崩壊する可能性が高まります。
低い数値だと、よりAIにとっての自由度が広がるため、いい結果を得られることもありますが、低すぎると希望した画像にならない可能性も高くなります。
基本的には使う学習モデルの推奨する数値を使うのが良いですが、5~9ぐらいが良く使われます
10.Seed
画像生成の計算に使用する乱数で、生成したイラストごとにランダムで割り振られる番号です。
Seed値を指定することで、同じイラストを何枚でも生成することができ、Seed値を固定したままモデルなどの条件を変えて生成することで、絵柄の違いが検証しやすくなります。
※最大値は4294967295
初期値で入力されている「-1」はランダムを意味します。
サイコロアイコン:Seed値を初期状態(-1)に戻す
リサイクルアイコン:最後に生成した画像のSeed値を呼び出す